Atomic Operation
多个线程访问相同的数据资源容易产生竞争条件,C++提供了互斥量来保护,强制同一时刻只有一个线程访问,使用条件变量在线程间同步并发操作。此外,C++11还提供了原子对象(atomic)是一个不可分割的数据对象,可以在线程间安全的存储(store)和加载(load),通过适当的内存顺序标记序偶在线程间同步。
原子操作的六种内存顺序选项:
- memory_order_relaxed
- memory_order_release
- memory_order_consume
- memory_order_acquire
- memory_order_acq_rel
- memory_order_seq_cst
Relaxed
以松散顺序执行的原子操作不参与同步(synchronize-with)关系,所以在线程间无法实现 happens-before 。memory_order_relaxed 只能保证不同线程并发对数据对象的操作是原子的,但是在不同的线程间看到该数据对象的值可以是不同的,一旦看到了该数据对象的特定值之后就不能获取该变量更早的值。不要被前面这一句话误导了,误认为像 exchange 等RMW(Read-Modify-Write)操作不会基于最新的值进行,对于任意内存顺序标记的RMW操作保证是基于其最新的值进行的。
Release / Consume
carries-a-dependency-to是指在同一个线程里指令间数据的依赖关系,如果操作A的结果被用作操作B的操作数,则Acarries-a-dependency-toB。dependency-order-beforem在线程1上以release存储,在线程2上以consume获取且读到线程1存储的值,称对m操作的指令在线程间存在dependency-order-before关系。
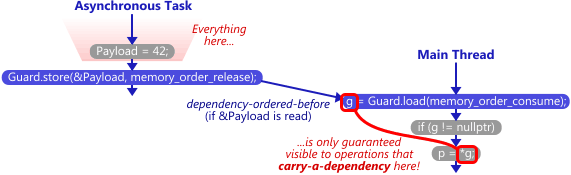
Release/Consume在线程间建立了 dependency-order-before 关系,如图所示,在Thread 1 store 之前对带有依赖的变量的操作结果在Thread 1上看到的,与Thread 2 load 后在Thread 2上看到的是一样的。
int payload = 0;
std::atomic<int*> guard = nullptr;
void write_thread() {
payload = 42; // #1
guard.store(&payload, std::memory_order_release); // #2
}
void read_thread() {
int* g = nullptr;
do {
g = guard.load(std::memory_order_consume); // #3
} while (!g);
std::cout << *g << std::endl; // 42
}
#1 carries-a-dependency-to #2, #2 dependency-order-before #3, 得到 #1 happens-before #3。
值得注意的是部分编译器并没有实现该语义,而是使用代价更高的 acquire 来代替。关于 consume 的详细介绍见《The Purpose of memory_order_consume in C++11》。
另,在某些条件下可以使用 std::kill_dependency() 显式地打破依赖链条。
Release / Acquire
sequence-before在同一个线程里两条指令间的关系,如果指令A在B之前,则Asequence-beforeB。synchronize-withm在线程1上以release存储,在线程2上以acquire获取且读到了线程1存储的值,则m在线程间存在synchronize-with关系。
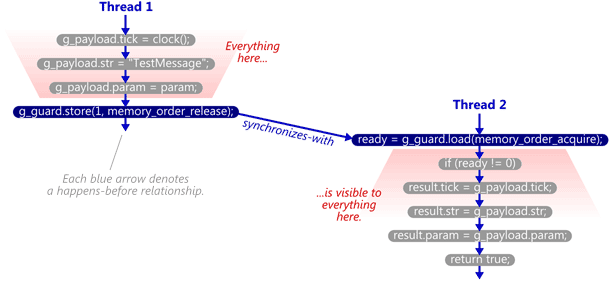
Release/Acquire是Release/Consume的进步,它在线程间建立了 synchronize-with 关系,如图所示,在Thread 1 store 之前对变量的操作结果在Thread 1上看到的,与Thread 2 load 后在Thread 2上看到的是一样的。
Release Sequence

如果 store 被标记为至少具有 release 内存顺序,而 load 被标记为至少具有 consume 内存顺序,并且链条中的每个操作都 load 到由之前操作 store 写入的值,那么该操作链条就构成了一个Release Sequence。如上图所示,虚线连接的操作是一个Release Sequence,consume_queue_items 之间的线程是不同步的,但是它们都与 populate_queue 的 count 保持同步,也就是说 consume_queue_items 的线程们之间不同步,但是它们中的任一线程对 count 的操作,其余的 consume_queue_items 都能看得到。
Sequential Consistency
std::atomic<bool> x = {false};
std::atomic<bool> y = {false};
std::atomic<int> z = {0};
void write_x() {
x.store(true, std::memory_order_seq_cst);
}
void write_y() {
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y() {
while (!x.load(std::memory_order_seq_cst));
if (y.load(std::memory_order_seq_cst)) {
++z;
}
}
void read_y_then_x() {
while (!y.load(std::memory_order_seq_cst));
if (x.load(std::memory_order_seq_cst)) {
++z;
}
}
int main() {
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join(); b.join(); c.join(); d.join();
assert(z.load() != 0); // will never happen
}
seq_cst 除了有Release/Acquire的效果,还会在所有的以这个为内存序的原子操作序列上外加一个单独全序,也就是保证所有的线程观察一组内存操作的顺序完全一样,这组内存操作是可以发生在不同的原子变量上的。
Memory Barries
std::atomic<Singleton*> Singleton::m_instance;
std::mutex Singleton::m_mutex;
Singleton* Singleton::getInstance() {
Singleton* tmp = m_instance.load(std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_acquire);
if (tmp == nullptr) {
std::lock_guard<std::mutex> lock(m_mutex);
tmp = m_instance.load(std::memory_order_relaxed);
if (tmp == nullptr) {
tmp = new Singleton;
std::atomic_thread_fence(std::memory_order_release);
m_instance.store(tmp, std::memory_order_relaxed);
}
}
return tmp;
}
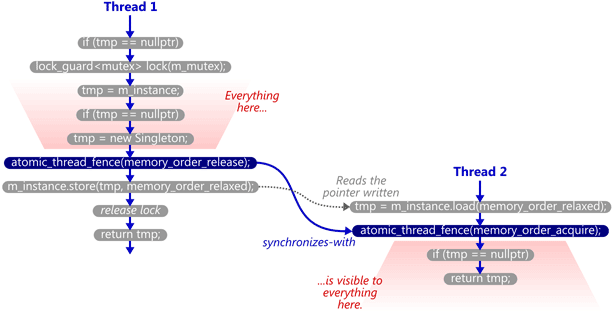
内存屏障可以在线程间强制内存顺序约束,而无需修改数据,与Relaxed组合起来使用,可以达到与Release/Acquire一样的效果。(区别是引入
std::atomic_thread_fence() 操作,而不通过修改数据在线程间同步。)
exchange_compare_weak vs exchange_compare_strong
exchange_compare_weak 可能会产生虚假失败,它需要伴随一个 while 循环使用,而 exchange_compare_strong 不会,那么为什么还要存在 exchange_compare_weak 呢?因为它具有更好的性能。当本来调用 exchange_compare 操作就需要在一个循环中执行时可以优先选择 weak 版本,否则就选择 strong 版本。
// desired 依赖于 expected 的函数,而且又一定要执行成功一次,这种情况使用 strong 版本也需要循环,那么优先选择 weak 版本。
expected = current.load();
do {
desired = function(expected);
} while (!current.compare_exchange_weak(expected, desired));
// 以下这种情况使用 strong 版本可以避免循环,没有必要使用 weak 版本。
expected = false;
// !expected: if expected is set to true by another thread, done!
// Otherwise, it fails spuriously and we should try again.
while (!current.compare_exchange_weak(expected, true) && !expected);
Understand std::atomic::compare_exchange_weak() in C++11
